俗话说前人栽树,后人乘凉,此话一点不假,结合云层的一遍文章:http://bbs.51testing.com/thread-533920-1-1.html,知道还有一个Tesseract-OCR可以用来识别图片上的文字(验证码)。
在code.google上下载了tesseract-ocr-setup-3.02.02.exe,即windows版本,下载安装后安装路径自动加入到环境变量中,在cmd中可以手动测试一下:
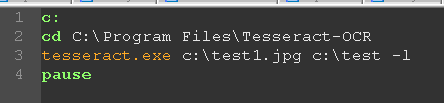
格式如下:tesseract.exe c:\test1.jpg c:\test -l
//test1.jpg 是我提前保存在C盘中的验证码图片,后面的test自动把test1.jpg中的验证码保存到test.txt中,后面-l是写入到test.txt文件中的。
按照云层提供的脚本,在system("c:\test.bat");无法运行,批处理脚本一闪就没有啦。修改了system("c:\\test.bat");,并修改了批处理文件,加入了pause,提示错误。如下图:

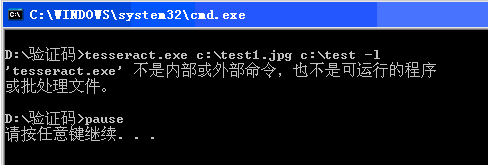
loadrunner工具不识别tesseract.exe命令,但是手动在任何目录中都是可以的,难道通过LR打开的终端窗口对windows中的path环境变量不识别??这个稍后严重。。
看样子只能修改这个批处理文件啦,把路径指定到tesseract的安装目录中去才可以。
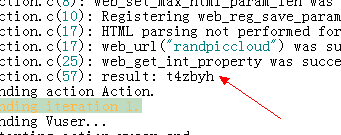
然后运行成功,在自动生成的test.txt中可以看到获取的验证码,也可以再LR的输出中看到验证码:t4zbyh

试了几个验证码,大多没有问题,
其中下面的不能被识别(2013年3月8日补充:并不是所有HTTPS的不能被识别,中信银行信用卡中心的验证码(纯数字的)就可以被识别https://creditcard.ecitic.com/citiccard/cppnew/jsp/valicode.jsp?time=1362724476515,一些验证码不被识别的原因还待摸索,为什么https纯数字的验证码就可以,难道其他的验证码是英文字符或者是加粗或者是图片太大的原因吗??):前面带有HTTPS的,
https://passport.csdn.net/ajax/verifyhandler.ashx?r_d=63178

下面是loadrunner脚本:现在C盘中建立test.bat批处理
Action(){ int flen; //定义一个整型变量保存获得文件的大小 long filedes; //保存文件句柄 char file[256]="c:\\test1.jpg"; //保存文件路径及文件名 char result[10]; //存放验证码的 web_set_max_html_param_len("2000000");//设置页面接收最大的字节数,该设置应大于下载文件的大小 web_reg_save_param("pic", "LB=", "RB=", "Ord=1", "Search=Body", LAST); web_url("randpiccloud","URL=https://passport.csdn.net/ajax/verifyhandler.ashx?r_d=63178",LAST); //http://biz.ftuan.com/CheckImg.aspx //http://passport.ftuan.com/SecurityCode.aspx?refresh=Wed Mar 6 11:21:21 UTC+0800 2013 //http://comment8.mydrivers.com/radompage.aspx?0.{rnum} //https://passport.gaopeng.com/captcha?w=98&h=36&r=0.4655476964544505 //https://passport.csdn.net/ajax/verifyhandler.ashx?r_d=63178 flen = web_get_int_property(HTTP_INFO_DOWNLOAD_SIZE); //获得文件大小 if(flen > 0) { if((filedes = fopen(file, "wb")) == NULL) { lr_output_message("oh cloud your Open File Failed!"); return -1; } fwrite( lr_eval_string("{pic}"),flen,1,filedes ); fclose( filedes ); } system("c:\\test.bat"); //调用C盘下的test.bat文件,改文件内容如下: /* c: cd C:\Program Files\Tesseract-OCR tesseract.exe c:\test1.jpg c:\test -l */ //首先下载Tesseract工具并安装,在批处理文件中必须cd到安装目录,否则LR调用时会提示“tesseract.exe不是内部命令” if((filedes = fopen("c:\\test.txt", "rt")) == NULL) { lr_output_message("oh,cloud your Open File Failed!"); return -1; } fread( result,5,1,filedes); //此处控制验证码的长度 fclose( filedes ); lr_output_message("result: %s",result); lr_save_string(result,"txtCheck"); //传验证码到txtCheck参数
lr_output_message("txtCheck: %s",lr_eval_string("{txtCheck}")); //lr_eval_string("{txtCheck}")用在下面的登录中
return 0;}
后续关注的问题是Tesseract-OCR识别图片的精确度,排除https协议的影响,目前识别验证码的精确度为70%左右,如果用在性能测试项目或者自动化测试项目中,将会大大降低工作效率的,并且system()调用批处理以及处理批处理也需要消耗时间。在正式测试时,尽量不要使用该工具,最好的办法是让研发开一个万能验证码或者去掉验证码功能。
好了,明天再研究吧。
近现代社会对电商网络的依赖程度越来越高,说不好有某些变态的测试需求,有可能在线上进行自动化测试,公司又有强硬的安全机制束缚,使用Tesseract-OCR来识别登录验证码或者注册验证码,支付时验证码等,还是有很大用处的。提高Tesseract-OCR识别的精确度是势在必行的。